Contents
23.3.11. 数据库:MySQL篇¶
mysql表设计
CREATE TABLE books(
upc CHAR(16) NOT NULL PRIMARY KEY,
name VARCHAR(256) NOT NULL,
price VARCHAR(16) NOT NULL,
review_rating INT,
review_num INT,
stock INT
)ENGINE INNODB DEFAULT CHARSET=utf8;
py连接mysql驱动
py测试脚本
# -*- coding: utf-8 -*-
import pymysql
#连接数据库,得到Connection对象
conn = pymysql.connect(host='localhost',user='root',db='scrapydb',port=3306,charset='utf8')
#创建Cursor对象,用于执行SQL语句
cursor = conn.cursor()
#创建数据表
##cursor.execute("CREATE TABLE person(name VARCHAR(32),age INT,sex char(1)) ENGINE INNODB DEFAULT CHARSET=utf8")
#插入一条数据
cursor.execute('INSERT INTO person VALUES(%s,%s,%s)',('李小龙',23,'M'))
#保存变更,commit后数据才会实际写入数据库
conn.commit()
#关闭连接
conn.close()
根据上篇的爬虫程序,稍作修改。
items.py文件保持不变
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BooksItem(scrapy.Item):
name = scrapy.Field() #书名
price = scrapy.Field() #价格
review_rating = scrapy.Field() #评价等级(1-5星)
review_num = scrapy.Field() #评价数量
upc = scrapy.Field() #产品编码
stock = scrapy.Field() #库存量
用sqlite3已经建立的项目,在此基础上修改代码,首先是pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# 爬取到的数据写入到MySQL数据库
import pymysql
class BooksPipeline(object):
review_rating_map = {
'One': 1,
'Two': 2,
'Three': 3,
'Four': 4,
'Five': 5
}
def process_item(self, item, spider):
# rating = item.get('review_rating') #获取review_rating的数据
rating = item['review_rating'] # 与上面的语句等价
item['review_rating'] = self.review_rating_map[rating]
return item
import pymysql
class MysqlPipeline(object):
# 打开数据库
def open_spider(self, spider):
db = spider.settings.get('MYSQL_DB_NAME', 'scrapy_default')
host = spider.settings.get('MYSQL_HOST', 'localhost')
port = spider.settings.get('MYSQL_PORT', 3306)
user = spider.settings.get('MYSQL_USER', 'root')
passwd = spider.settings.get('MYSQL_PASSWORD', 'admin#123')
self.db_conn = pymysql.connect(host=host, port=port, db=db, user=user, passwd=passwd, charset='utf8')
self.db_cur = self.db_conn.cursor()
# 关闭数据库
def close_spider(self, spider):
self.db_conn.commit()
self.db_conn.close()
# 对数据进行处理
def process_item(self, item, spider):
self.insert_db(item)
return item
# 插入数据
def insert_db(self, item):
values = (
item['upc'],
item['name'],
item['price'],
item['review_rating'],
item['review_num'],
item['stock']
)
sql = 'INSERT INTO books VALUES(%s,%s,%s,%s,%s,%s)'
self.db_cur.execute(sql, values)
settings.py
MYSQL_DB_NAME = 'scrapydb'
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
ITEM_PIPELINES = {
'books.pipelines.BooksPipeline': 300,
# 'books.pipelines.SQLitePipeline': 400,
'books.pipelines.MysqlPipeline': 401,
}
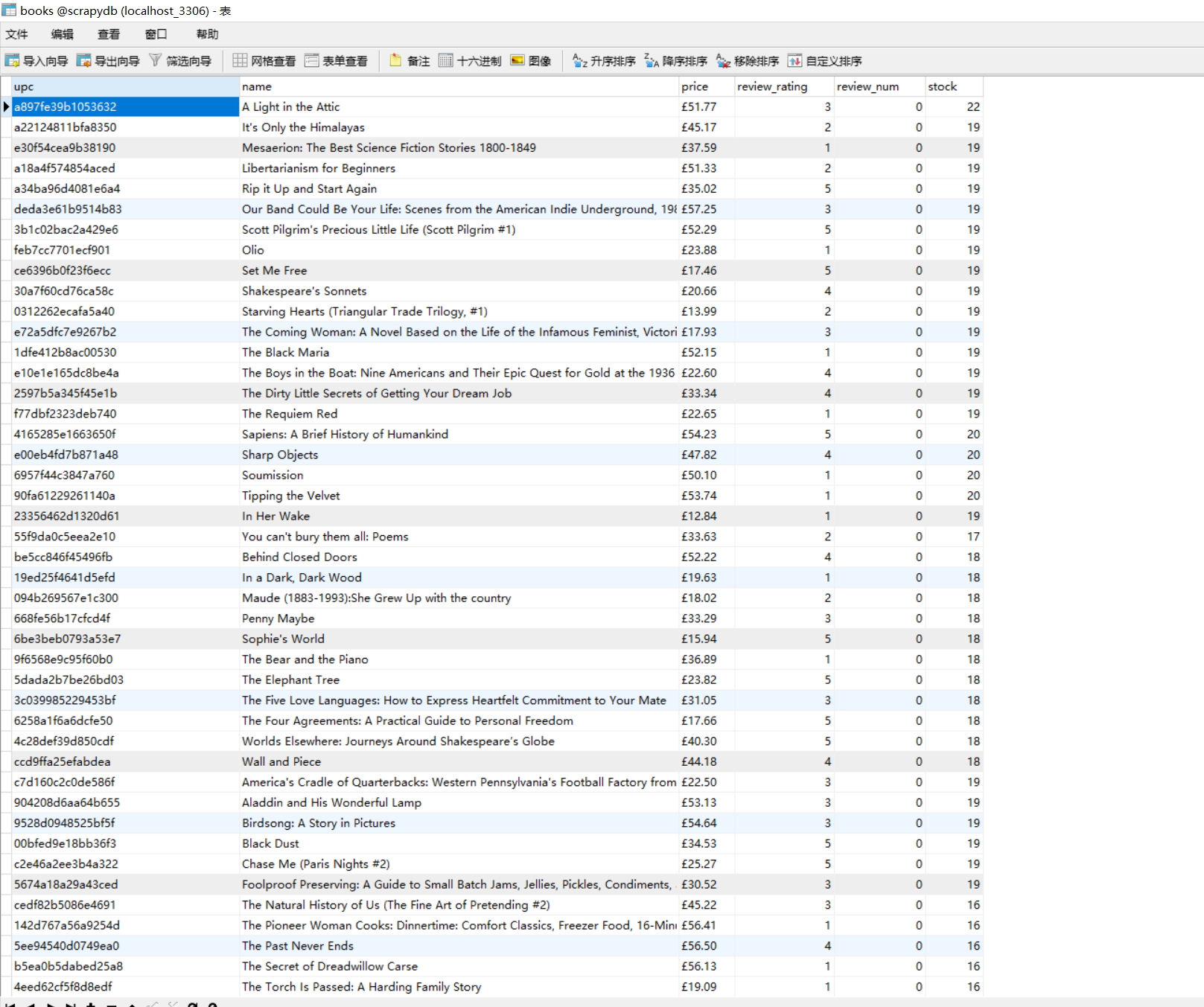
运行scrapy crawl booksspider,查看数据库内容是否保存。
数据信息如下: